Hashing
Hashing is a technique to convert a range of key values into a range of indexes of an array. We're going to use modulo operator to get a range of key values. Consider an example of hash table of size 20, and the following items are to be stored. Item are in the (key,value) format.
Hash function
A hash function is any function that can be used to map a data set of an arbitrary size to a data set of a fixed size, which falls into the hash table. The values returned by a hash function are called hash values, hash codes, hash sums, or simply hashes.
To achieve a good hashing mechanism, It is important to have a good hash function with the following basic requirements:
- Easy to compute: It should be easy to compute and must not become an algorithm in itself.
- Uniform distribution: It should provide a uniform distribution across the hash table and should not result in clustering.
- Less collisions: Collisions occur when pairs of elements are mapped to the same hash value. These should be avoided.
Note: Irrespective of how good a hash function is, collisions are bound to occur. Therefore, to maintain the performance of a hash table, it is important to manage collisions through various collision resolution techniques.
Hashing is implemented in two steps:
An element is converted into an integer by using a hash function. This element can be used as an index to store the original element, which falls into the hash table.
The element is stored in the hash table where it can be quickly retrieved using hashed key.
hash = hashfunc(key)
index = hash % array_size
In this method, the hash is independent of the array size and it is then reduced to an index (a number between 0 and array_size − 1) by using the modulo operator (%).
Need for a good hash function
Let us understand the need for a good hash function. Assume that you have to store strings in the hash table by using the hashing technique {“abcdef”, “bcdefa”, “cdefab” , “defabc” }.
To compute the index for storing the strings, use a hash function that states the following:
The index for a specific string will be equal to the sum of the ASCII values of the characters modulo 599.
As 599 is a prime number, it will reduce the possibility of indexing different strings (collisions). It is recommended that you use prime numbers in case of modulo. The ASCII values of a, b, c, d, e, and f are 97, 98, 99, 100, 101, and 102 respectively. Since all the strings contain the same characters with different permutations, the sum will 599.
The hash function will compute the same index for all the strings and the strings will be stored in the hash table in the following format. As the index of all the strings is the same, you can create a list on that index and insert all the strings in that list.
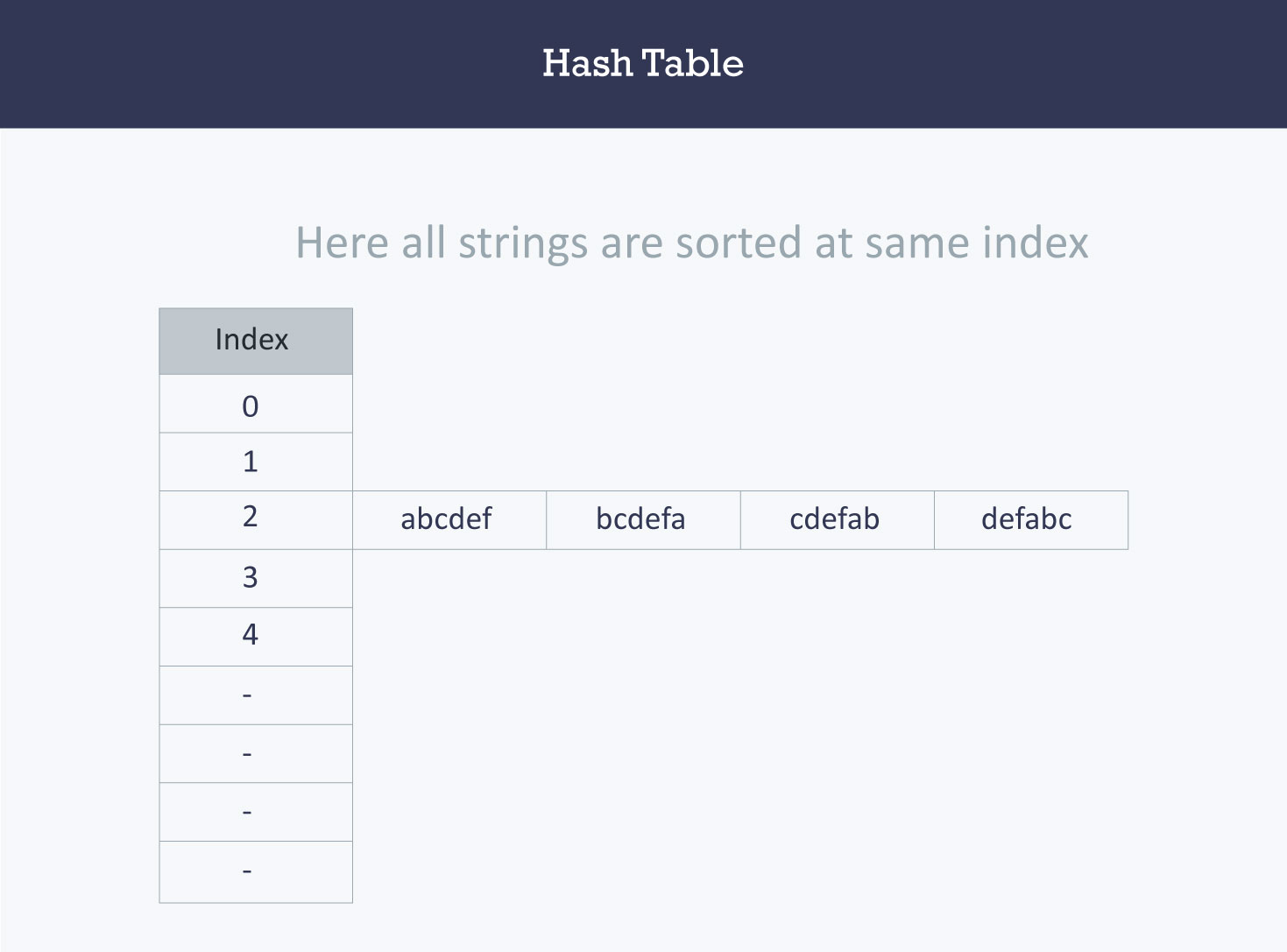
Here, it will take O(n) time (where n is the number of strings) to access a specific string. This shows that the hash function is not a good hash function.
Let’s try a different hash function. The index for a specific string will be equal to sum of ASCII values of characters multiplied by their respective order in the string after which it is modulo with 2069 (prime number).
String Hash function Index
abcdef (971 + 982 + 993 + 1004 + 1015 + 1026)%2069 38
bcdefa (981 + 992 + 1003 + 1014 + 1025 + 976)%2069 23
cdefab (991 + 1002 + 1013 + 1024 + 975 + 986)%2069 14
defabc (1001 + 1012 + 1023 + 974 + 985 + 996)%2069 11
Binary Trees
Types of Binary Trees
1. Perfect Binary Tree - a binary tree which has the same depth on every level, or there are not "missing nodes" on the tree
2. Complete Binary Tree - "missing nodes" can occur only on the last level
3. Skewed Binary Tree - each node only has one child
4. Balanced Binary Tree - no leaf is much farther away from the root than any other leaf
Properties
1. Maximum number of nodes on any level is 2 to the power of the level
2. maximun number of nodes on a binary tree is 2 to the power of height subtracted by 1.
3. Minimun height of a binary tree for n nodes is 2log(n)
4. Maximum height of a binary tree of n nodes is n -1
Representation
1. Array
- Index 0 is the Root node
- Left child is 2p+1, where p is the parent index
- Right child is 2p+2, where p is the parent index
- Index parent is (p-1)/2
2. Linked List
- We need a left pointer
- We need a right pointer
- A parent pointer can also be added if you want
No comments:
Post a Comment